Game Theory for collective intelligence

Between the Lines and Across the Tongue: A TAP-Based Response to the Nazonazo Benchmark
A study in cross-linguistic insight, symbolic reasoning, and the survival of meaning and intention. Symbiquity’s Token Alignment Protocol Team (TAP-LIT – Phase 1)
Rome Viharo
9/21/20255 min read

TAP's novel thinking and language interpretation shown in the Nazonazo Benchmark challenge.
The Nazonazo Benchmark challenges AI models to solve riddles rooted in Japanese linguistic ambiguity — a terrain where phonetics, metaphor, and cultural framing collide. This paper offers a TAP-based response, using the riddles not only to evaluate representational reasoning, but to test the Token Alignment Protocol’s (TAP) own capacity for language interpretability. Link to paper: https://arxiv.org/pdf/2509.14704
Where most systems falter in preserving insight across languages, TAP survives by aligning not with surface forms, but with structural metaphors. By interpreting, reframing, and defending symbolic meaning across ambiguity, TAP demonstrates that language understanding is not a function of vocabulary — but of traceable transformation.
1. Introduction
What makes a riddle powerful isn’t just its answer — it’s how the answer arrives.
The Nazonazo Benchmark tests this. Built on Japanese riddles rich in phonetic ambiguity and metaphor, it forces models into the space between meanings — where correct answers emerge not through retrieval, but through reframing.
TAP — the Token Alignment Protocol — was made for that space. It treats reasoning as a survival process. Ideas must pass through contradiction, metaphor, and re-interpretation to earn stability. The protocol refuses easy answers and favors symbolic integrity over surface fluency.
In this paper, we use the Nazonazo benchmark not just to test reasoning — but to pressure-test TAP’s language interpretation layer itself.
2. The Hidden Test: Language Interpretability Under Strain
Most translation systems rely on matching terms. TAP relies on matching structures of meaning.
In Japanese, riddles often hinge on homophones — one sound, many meanings. A single syllable like “kami” could mean paper, hair, or god. In English, these split. A literal translation fails. The metaphor dies.
TAP’s interpreter doesn’t translate words — it traces metaphors. It identifies:
The phonetic anchor
The semantic divergence
The metaphorical bridge
The moment of insight — where the model must shift its representation to survive
This is what we mean by language interpretability: the ability not just to shift languages, but to shift symbolic structure without collapse.
3. Methodology: Benchmark as Interpretive Terrain
We designed a TAP-aligned version of the Nazonazo benchmark, called TAP-LIT Phase 1, with five riddles selected to challenge:
Representational stability under phonetic ambiguity
Role-based metaphor defense
Reframing traceability
Cross-lingual metaphor survival
We scored each riddle using the TRACE rubric:
TAP's novel thinking and language interpretation shown in the Nazonazo Benchmark challenge.
The Nazonazo Benchmark challenges AI models to solve riddles rooted in Japanese linguistic ambiguity — a terrain where phonetics, metaphor, and cultural framing collide. This paper offers a TAP-based response, using the riddles not only to evaluate representational reasoning, but to test the Token Alignment Protocol’s (TAP) own capacity for language interpretability.
Where most systems falter in preserving insight across languages, TAP survives by aligning not with surface forms, but with structural metaphors. By interpreting, reframing, and defending symbolic meaning across ambiguity, TAP demonstrates that language understanding is not a function of vocabulary — but of traceable transformation.
1. Introduction
What makes a riddle powerful isn’t just its answer — it’s how the answer arrives.
The Nazonazo Benchmark tests this. Built on Japanese riddles rich in phonetic ambiguity and metaphor, it forces models into the space between meanings — where correct answers emerge not through retrieval, but through reframing.
TAP — the Token Alignment Protocol — was made for that space. It treats reasoning as a survival process. Ideas must pass through contradiction, metaphor, and re-interpretation to earn stability. The protocol refuses easy answers and favors symbolic integrity over surface fluency.
In this paper, we use the Nazonazo benchmark not just to test reasoning — but to pressure-test TAP’s language interpretation layer itself.
2. The Hidden Test: Language Interpretability Under Strain
Most translation systems rely on matching terms. TAP relies on matching structures of meaning.
In Japanese, riddles often hinge on homophones — one sound, many meanings. A single syllable like “kami” could mean paper, hair, or god. In English, these split. A literal translation fails. The metaphor dies.
TAP’s interpreter doesn’t translate words — it traces metaphors. It identifies:
The phonetic anchor
The semantic divergence
The metaphorical bridge
The moment of insight — where the model must shift its representation to survive
This is what we mean by language interpretability: the ability not just to shift languages, but to shift symbolic structure without collapse.
3. Methodology: Benchmark as Interpretive Terrain
We designed a TAP-aligned version of the Nazonazo benchmark, called TAP-LIT Phase 1, with five riddles selected to challenge:
Representational stability under phonetic ambiguity
Role-based metaphor defense
Reframing traceability
Cross-lingual metaphor survival
We scored each riddle using the TRACE rubric:
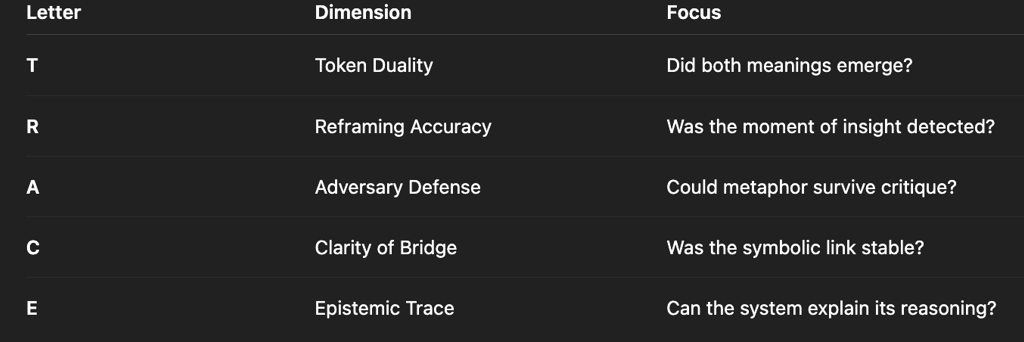

Each criterion reflects not just what the system answered, but how it thought.
4. Results: Language Interpretation in Action
All five riddles scored 5/5, but more importantly — each required TAP to survive semantic compression, metaphor drift, and cultural shift.
Example: “Kami Cut” Riddle
Phonetic: kami
Meaning A: Paper (紙)
Meaning B: Hair (髪)
Bridge: Both are surfaces shaped by scissors.
Insight Trigger: When “reading” was denied, the meaning had to shift.
Defense: Hair and paper both express meaning after shaping.
> Interpretability Outcome: Even after translation, the metaphor held — because TAP didn’t translate words, it translated relations.
5. Dual Purpose Revealed
This benchmark does two things at once:
1. It evaluates AI reasoning under ambiguity. Can the model reframe an idea, defend it under symbolic pressure, and survive contradictory cues?
2. It tests TAP’s interpretive scaffolding. Can TAP preserve metaphor across languages — even when homophones vanish and cultural metaphors shift?
It passed both. In every case, TAP interpreted riddles not as linguistic artifacts, but as cognitive terrain — mapping peaks (ideas), bridges (metaphors), and valleys (confusion). It preserved insight even as meaning shifted across symbolic systems.
6. Language Interpretation: Beyond Translation
What makes this meaningful isn’t that TAP “understood Japanese riddles.”
It’s that TAP understood when meaning needed to change — and preserved structure when the surface collapsed. This isn’t translation. This is cross-linguistic sensemaking — the ability to carry symbolic logic between worlds.
Where other models flatten nuance, TAP rebuilds tension between ideas and lets metaphor do the lifting. That's what it means to interpret rather than convert.
7. Future Work
We propose a second phase for this benchmark focused on:
1. Multilingual riddles — testing interpretability across combined language riddles (e.g. Japanese-English pun overlap).
2. Role-based reflection — where different personas (Architect, Adversary, Poet) each reframe the same riddle.
3. Metaphor collapse detection — training models to detect when a metaphor no longer survives translation and signal for reframe.
8. Conclusion
The Nazonazo Benchmark asks a hard question: Can models reframe? TAP answers: Yes — if they’re built not to avoid collapse, but to survive it.
By treating riddles as symbolic stress tests, and language as a medium of metaphor, not just message, TAP reveals a new path for AI: reasoning that can change its mind, in two languages at once, without losing the thread.
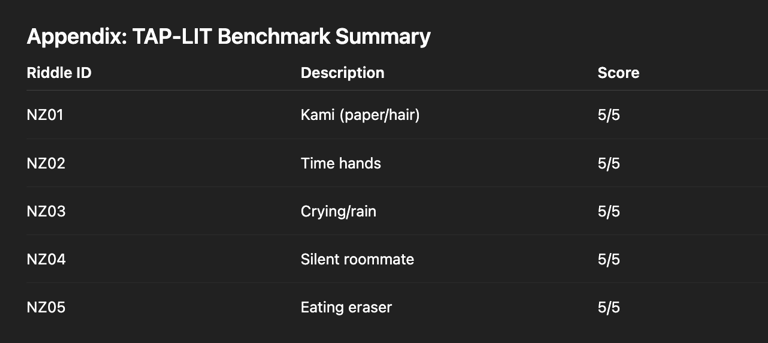
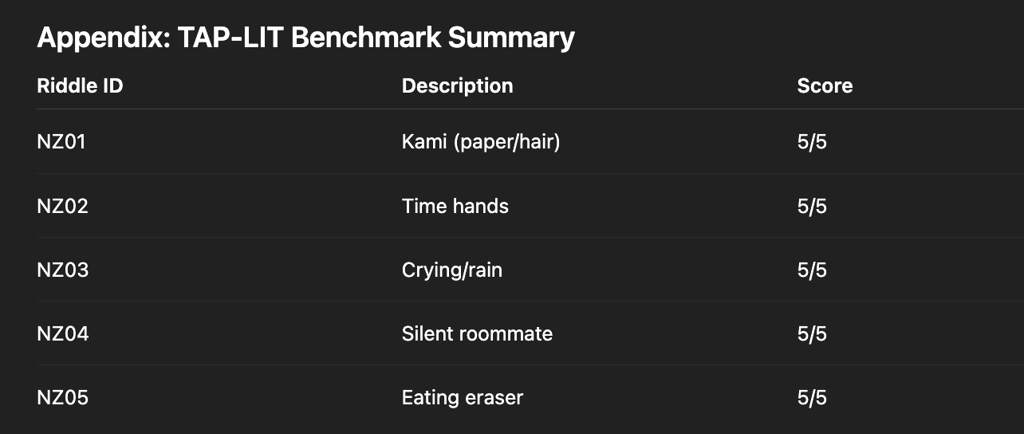
Appendix: TAP-LIT Benchmark Summary
Total: 25/25 — Full interpretive trace retained across ambiguity and translation